Speech Synthesis From Continuous Features Using Per-Token Latent Diffusion
ASRU 2025
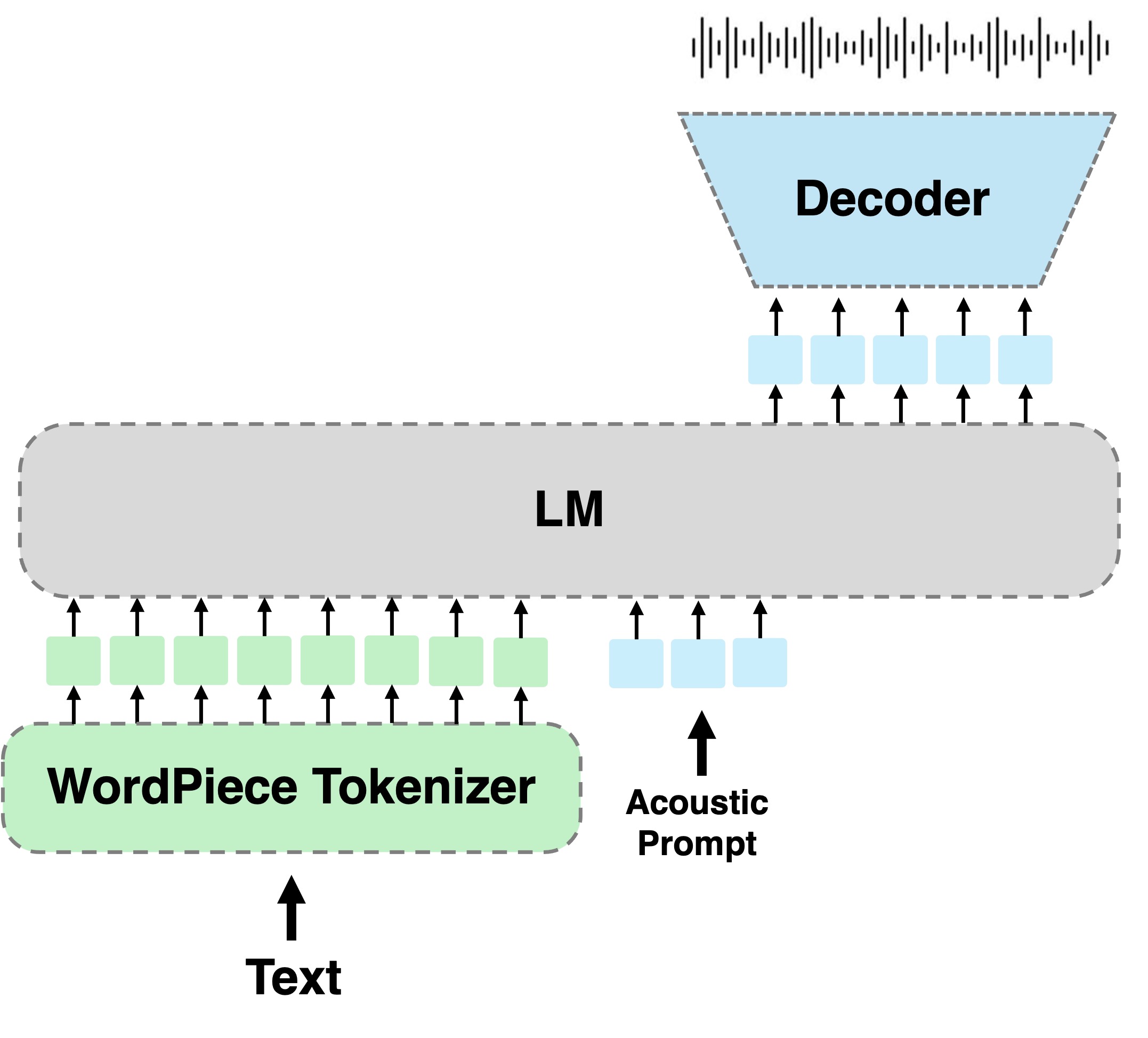
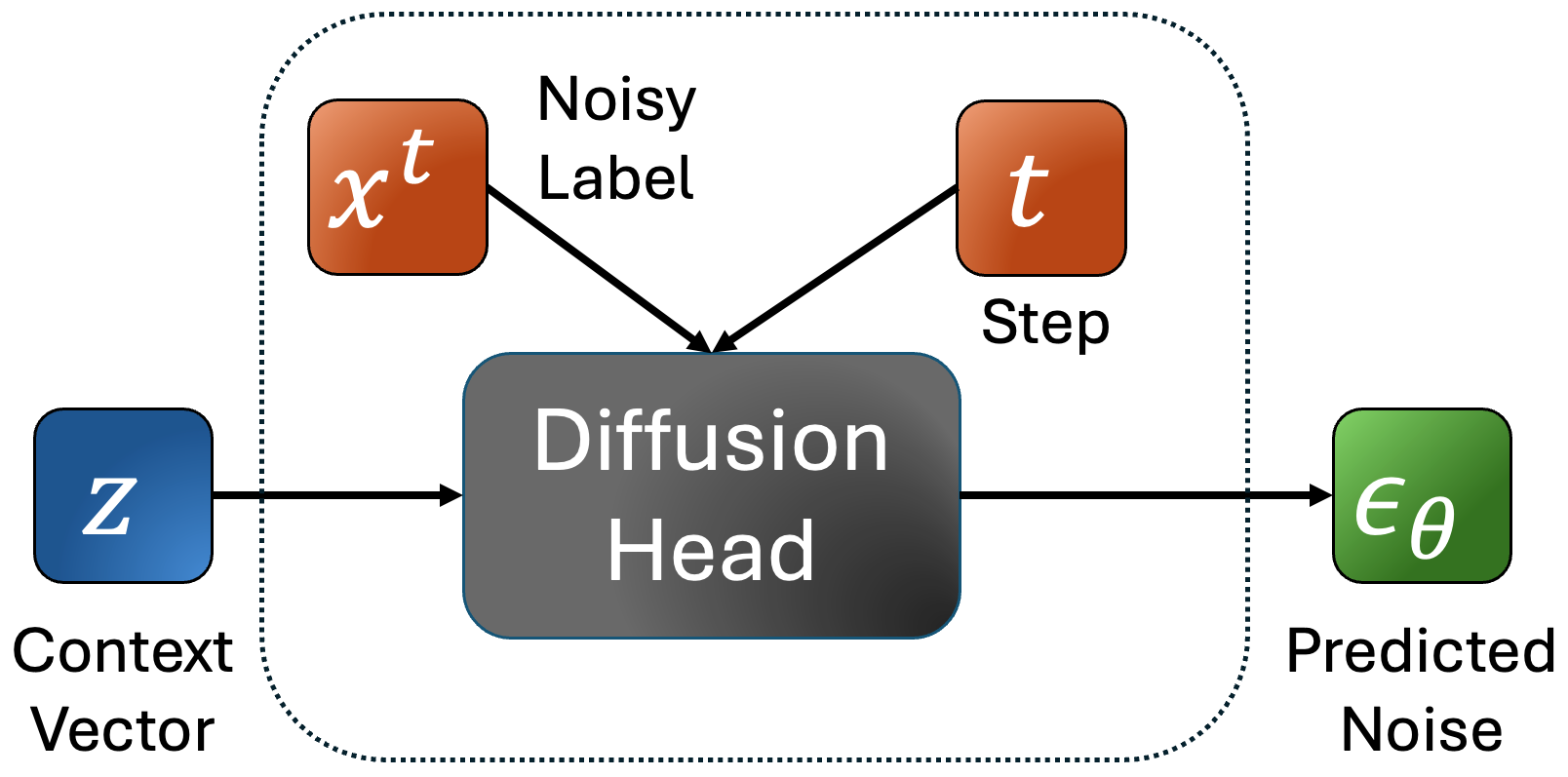
SALAD is a per-token latent diffusion model for zero-shot text-to-speech,that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition.